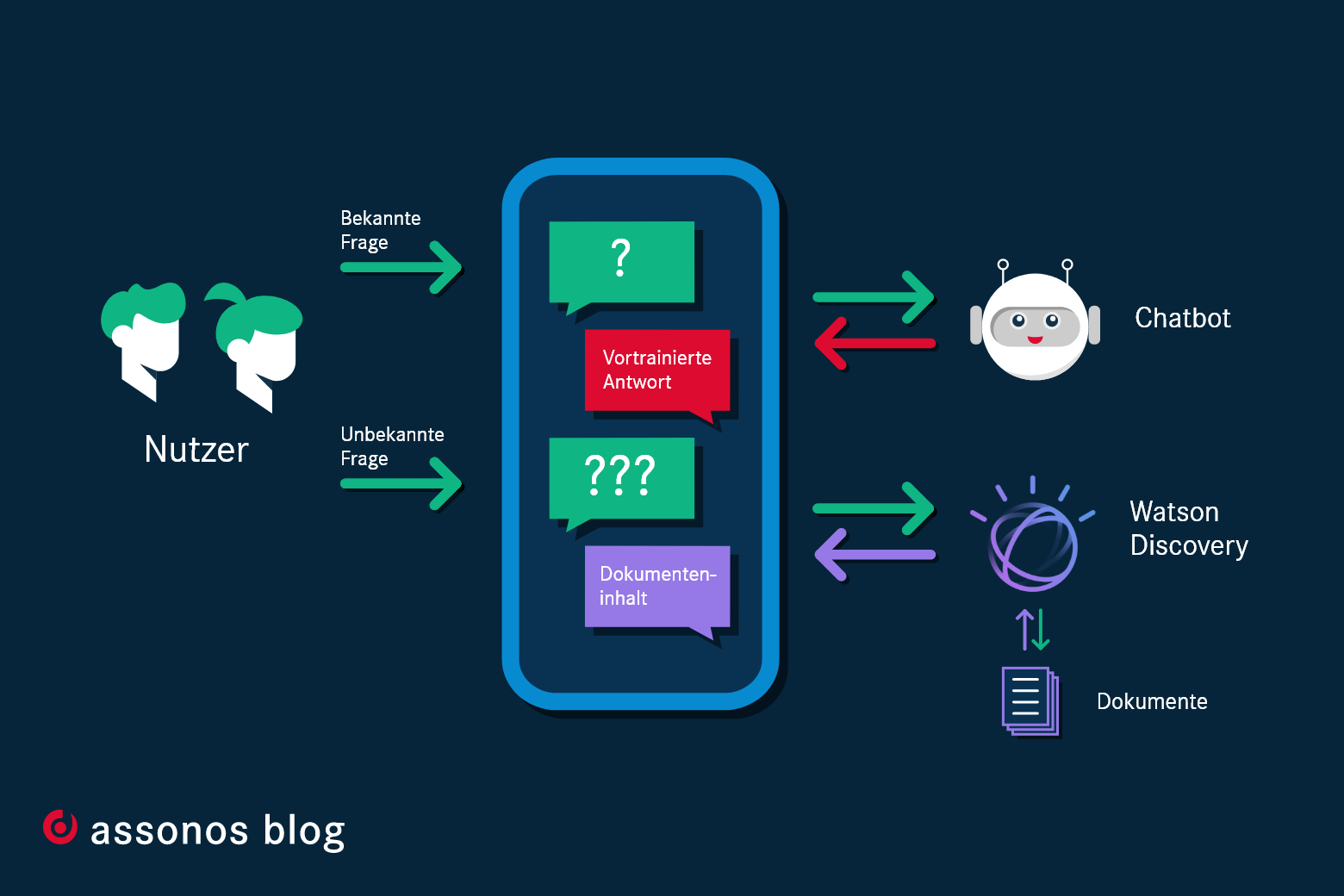
Was tun, wenn der Chatbot keine Antwort geben kann?
Grundsätzlich gilt: Wer einen schlauen Chatbot einsetzen möchte, der sollte zunächst Zeit investieren um dem Bot eine ganze Menge an passenden Antworten auf die anfallenden Nutzerfragen (Kundenfragen an den Bot) beibringen zu können. Und selbst wenn man denkt man hätte alles an Antworten abgedeckt, so werden dem Bot doch immer wieder neue Fragen gestellt, an die man dann doch noch nicht gedacht hatte und auf welche der Bot dann natürlich auch noch nicht trainiert worden ist (der Bot hier also noch keine passende Antwort geben kann).
Für Unternehmen, die sehr viele Informationen als Texte in verschiedenen Formaten und an verschiedenen Orten vorliegen haben, diese aber nicht alle einzeln in ggf. tausenden von Chatbot Antworten neu formulieren wollen, lohnt sich ein Blick auf die KI-Technologie "Watson Discovery" von IBM: Allgemein ist Watson Discovery ist eine ausgezeichnete Technologie im Bereich der KI-Suche, die Datensilos aufbricht und präzise Antworten auf Fragen abruft sowie verborgene Trends und Zusammenhänge in Unternehmensdaten erkennt und analysiert. Watson Discovery nutzt die neuesten Fortschritte in maschinellem Lernen, darunter Funktionen für die Verarbeitung natürlicher Sprache.
IBM Watson Discovery kann direkt an den assono KI-Chatbot angebunden werden und dann selbstständig nach Antworten in diversen Datenquellen suchen, diese analysieren und die Ergebnisse dann als Antwort wieder über den Chatbot ausgeben. Ein großer Mehrwert also für Chatbot Nutzer, die so immer direkt eine passende Antwort bekommen, als auch für die Unternehmen, die Chatbots mit Watson Discovery einsetzen, da diese im Training des Bots erheblich an Zeiteinsparungen gewinnen. Im Folgenden zeigen wir auf, wie Unternehmen einen Chatbot in nur vier Schritten mit einer Integration von IBM Watson Discovery schlauer machen können:
Schritt 1: Identifikation der Datenlage
Die grundsätzliche Frage, die man sich im ersten Schritt stellen sollte, ist, ab welchem Punkt ein Chatbot unverhältnismäßig viel trainiert werden würde, wenn die Daten bereits fertig aufbereitet vorliegen.
Ein Beispiel: Aus einer FAQ-Website, die um die 50 Fragen umfasst, müssen all diese Fragen optimalerweise in mehreren Formulierungen trainiert werden, um die gesamten FAQ abzudecken. Die Vorgehensweise ist inhaltlich und bildet direkt jede einzelne FAQ-Frage ab – und dies auch mit sehr guter Erfolgsquote im fertigen Chatbot. Das geht mit unserem Chatbot-Dashboard natürlich auch sehr einfach, aber bei den passenden Datenformen steht hier eine weitere Abkürzung offen. Einem Chatbot mit Discovery-Integration reicht hier ein kleinerer Katalog aus potenziellen oder tatsächlichen Fragen aus dem FAQ, denn Discovery lernt nicht auf Inhalten, sondern auf Basis der dem Dienst beigebrachten Datenstrukturen.
Im ersten Schritt erfolgt also die Identifikation der Datenlage:
- Welche Daten liegen bereits vor?
- Welche davon sind für die Zielgruppe meines Chatbots relevant?
- Liegen vorstrukturierte Daten vor, deren Segmente ich direkt beim Training aufgreifen kann?
- Wie viel Arbeit wäre es, all diese Daten manuell einzutrainieren oder kann einiges davon automatisiert verarbeitet werden?
- Ab welchem Punkt empfiehlt sich durch den Aufwand eines Chatbot-Trainings die Nutzung einer automatischen Suchfunktion über die vorliegenden Daten?
- Bei welchen Arten von Fragen soll der Chatbot an Discovery abgeben statt vortrainierte Antworten zu verwenden?
In diesem Fall können die Daten bspw. folgender Natur sein:
- öffentliche Websites mit textueller Information
- PDF- und Worddokumente wie Anleitungen, Handbücher
- als umfassendere Quellen z.B. Cloud-Speicher, Online-Laufwerke
- Bilder, Grafiken und PDF-Scans, die mit einer eingebauten Texterkennung automatisch verschriftlicht werden
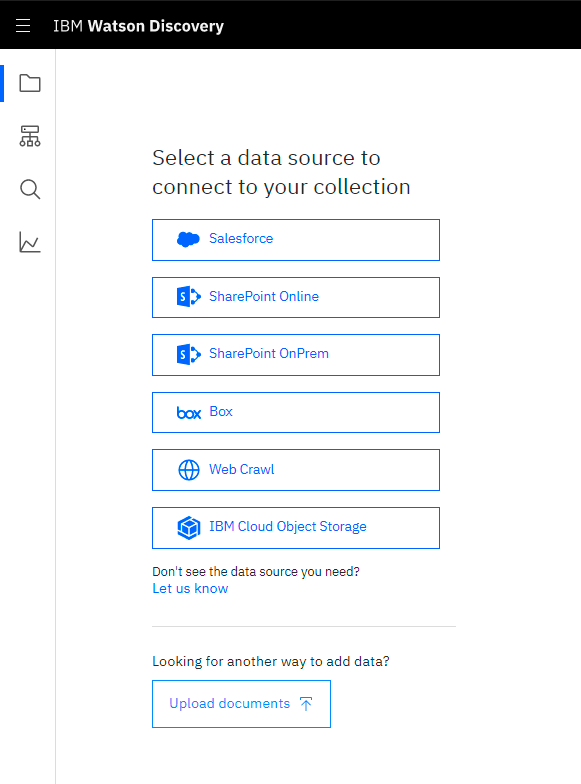
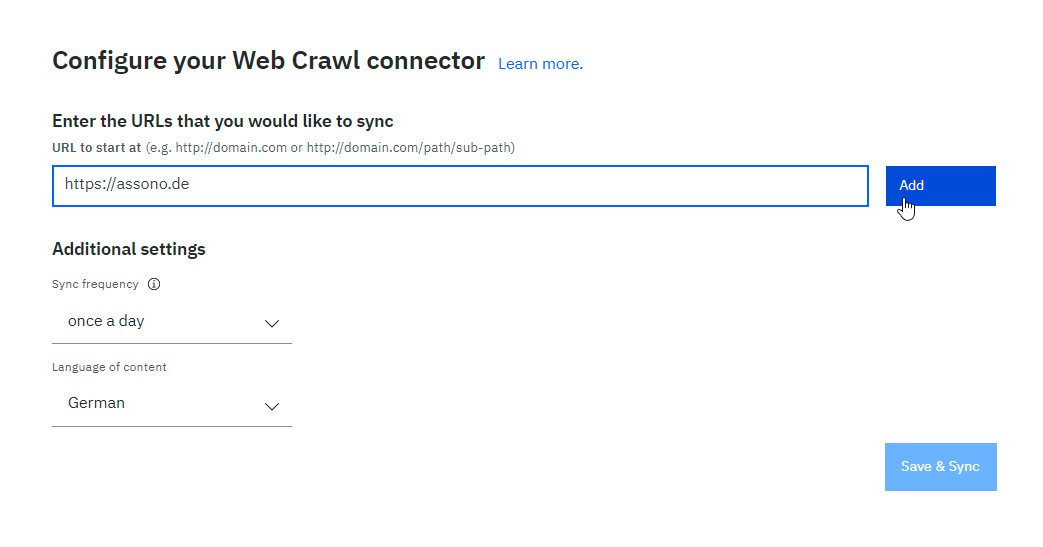
Schritt 2: Anbindung der Daten
Im zweiten Schritt erfolgt die Aufnahme der ausgewählten Daten auf die denkbar einfachste Weise: über eine Web-Oberfläche per Upload-Funktion im Fall von Dokumenten und per ULR im Fall von Websites oder Cloud-Speichern. Bei der Nutzung von öffentlichen Websites können durch die Veränderung der URL spezielle Bereiche eingegrenzt werden, um nichts für den Chatbot Irrelevantes einzulesen – so reicht es dann bspw. auch, nur die Unterseiten https://ihre-website.com/faq oder https://ihre-website.com/blog auszulesen. Die Häufigkeit der Aktualisierung lässt sich ebenso festlegen wie die Sprache der Websitequelle. Im Fall von Dokumenten wie Handbüchern, Journal-Artikeln, Informationstexten, Korrespondenz etc. erfolgt ein direkter Upload oder eine Freigabe eines Cloud-Speichers über die Web-Oberfläche.
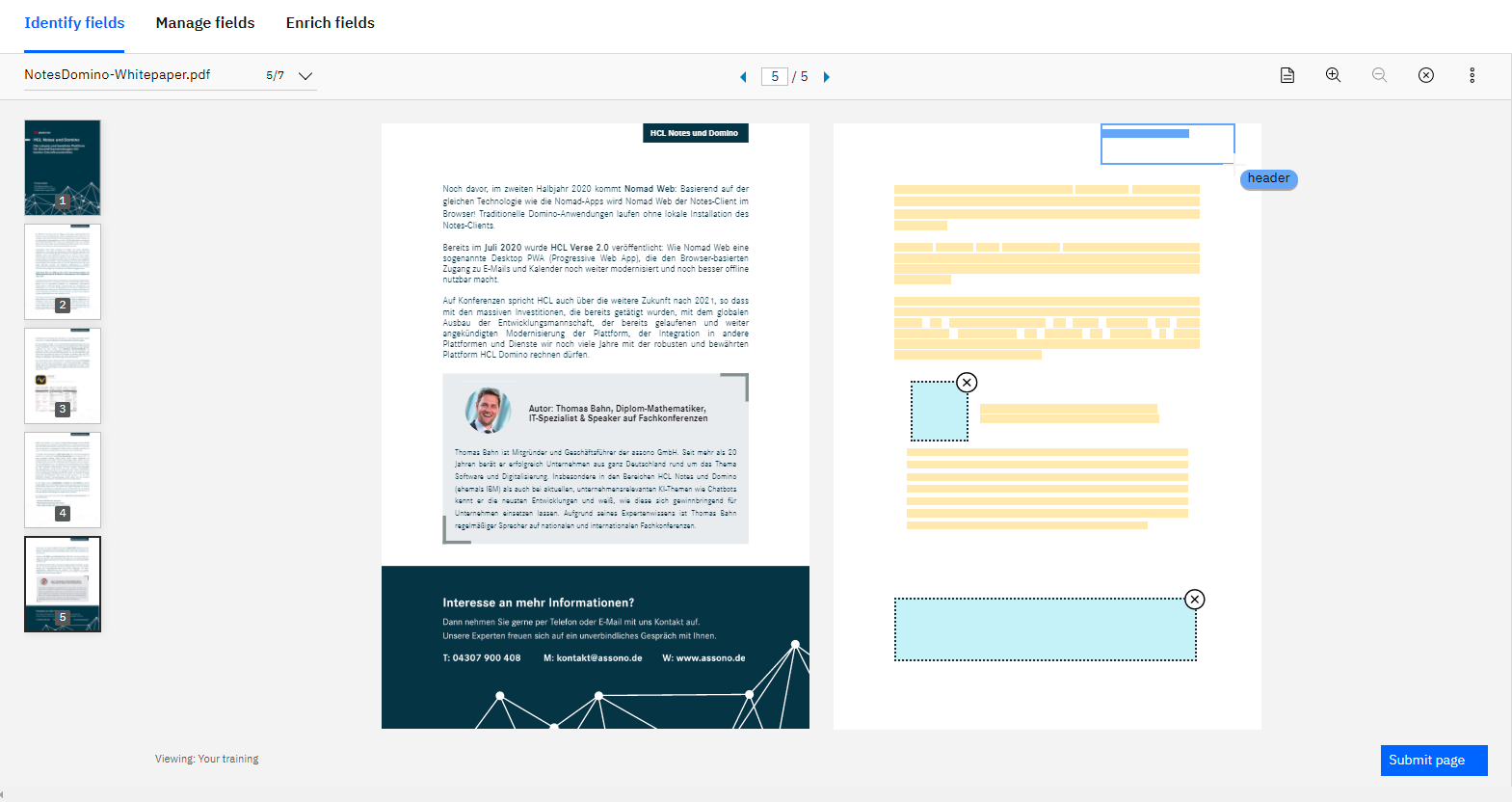
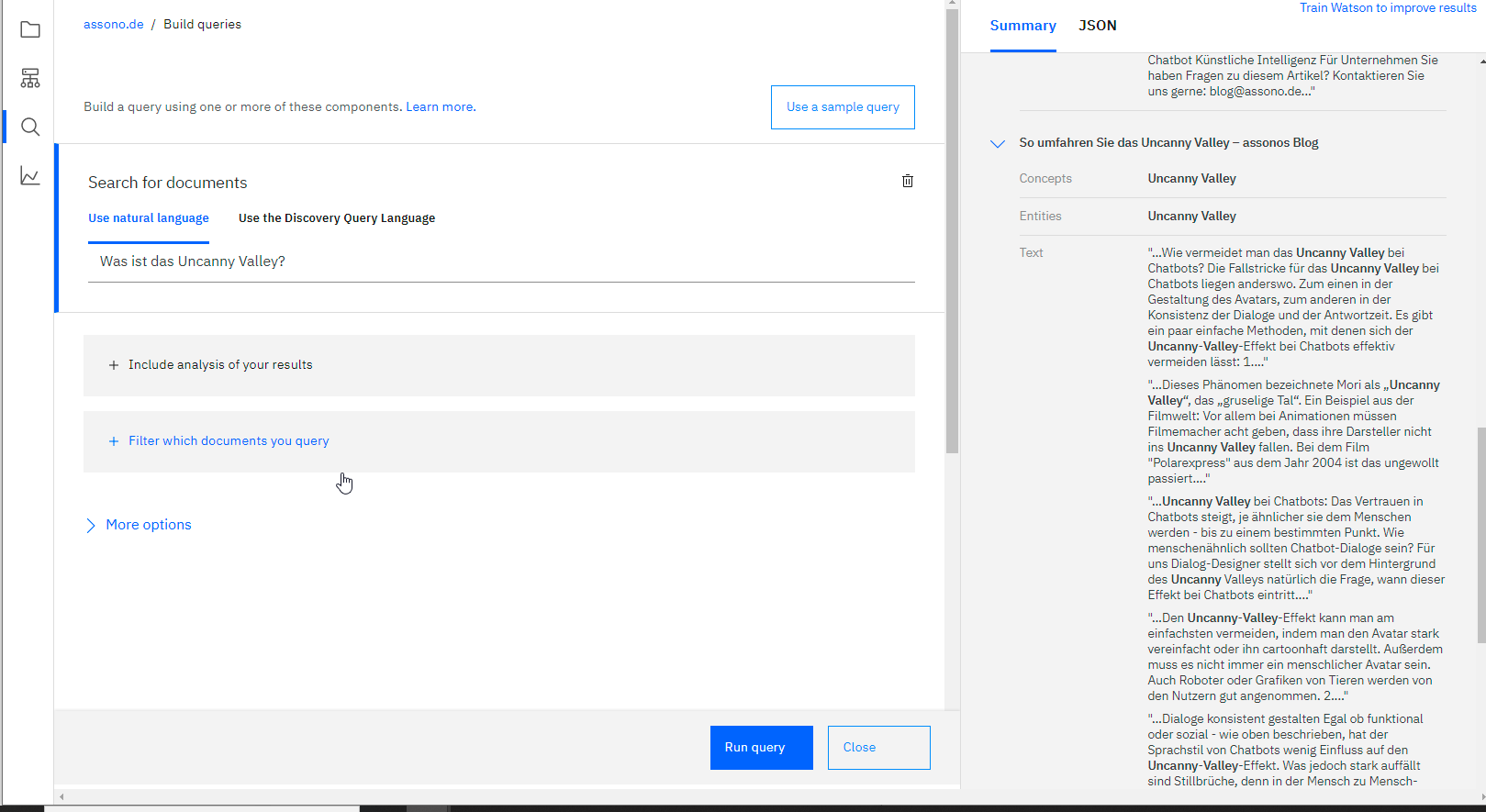
Schritt 3: Anreichern und Trainieren
Der wichtigste Punkt der Vorbereitung des Discovery-Chatbots wird in Schritt 3 erreicht: das Training der eingelesenen Daten, also die Unterstützung der automatischen Anreicherung und Klassifizierung durch menschliche Eingaben.
Grundsätzlich sind zwei Arten des Trainings zu unterscheiden, die einzeln oder aufeinander aufbauend angewendet werden:
- Segmentierungstraining auf Dokumententypen bei PDFs, über die Web-Funktion „Smart Document Understanding“. Erfahrungsgemäß ist nach ca. 10 fertig zugeordneten PDF-Dokumenten unterschiedlicher Beschaffenheiten eine erste korrekte Einordnung der restlichen Daten problemlos möglich.
- Antworttraining: Es werden potentiell ankommende Anfragen generiert und diesen dann passende Ergebnisse zugeordnet. Dabei wird unterschieden zwischen „relevant“ und „nicht relevant“, die Einordnung hilft dem Dienst dabei, bessere Vorschläge zu machen. Nach ca. 50 Fragen, was etwa einem Nachmittag Arbeit einer Person, die mit den zugrundeliegenden Daten vertraut ist, entspricht, ist Discovery vollständig trainiert und verbessert seine Vorschläge merklich.
Die Vorteile liegen hier auf der Hand: keine einzige Zeile Code muss zur Erstellung eines Chatbots geschrieben werden, um die volle Power einer KI-Anwendung zur Entfaltung zu bringen, alles läuft über die einfach bedienbare Web-Oberfläche.
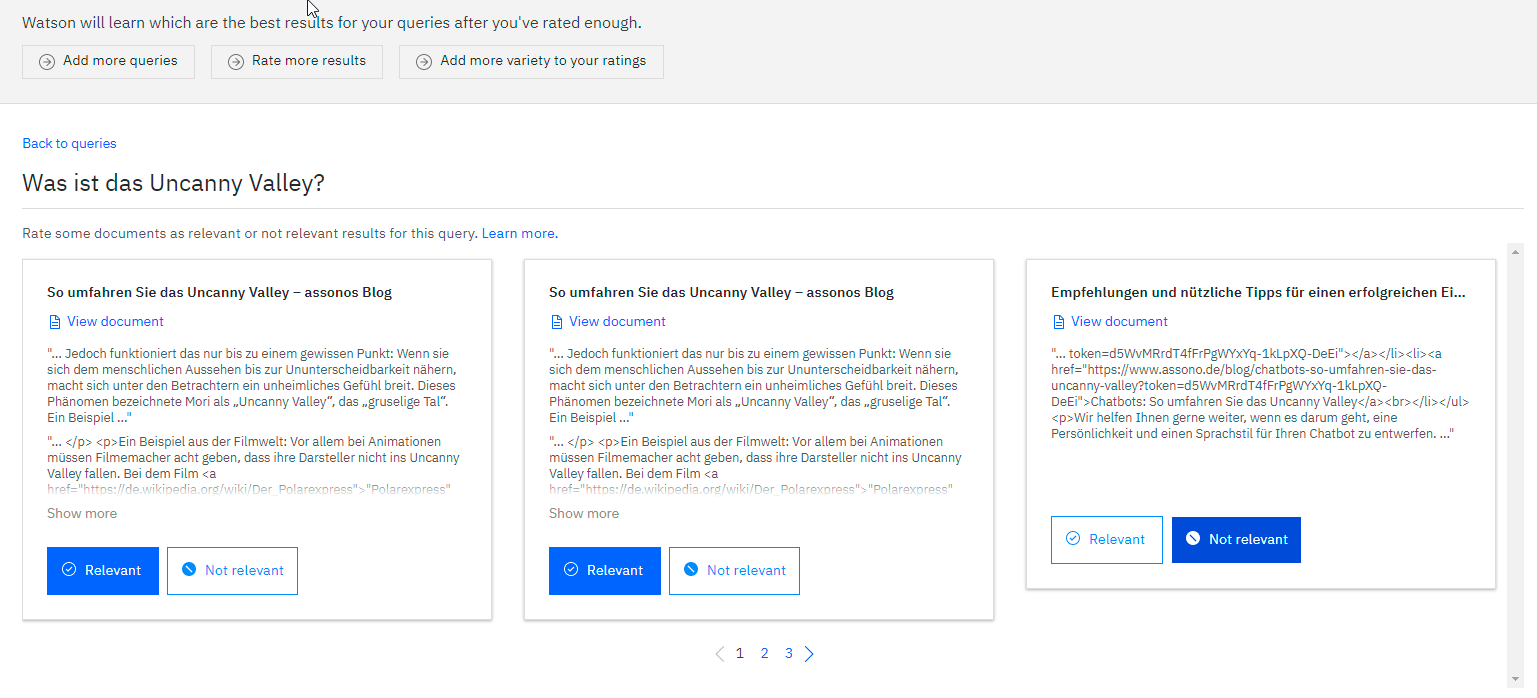
Schritt 4: Fragen, Fragen, Fragen
Wie laufen nun alle diese Informationen und angereicherten Daten in einem nutzbaren Frontend zusammen, das direkt die Zielgruppe anspricht?
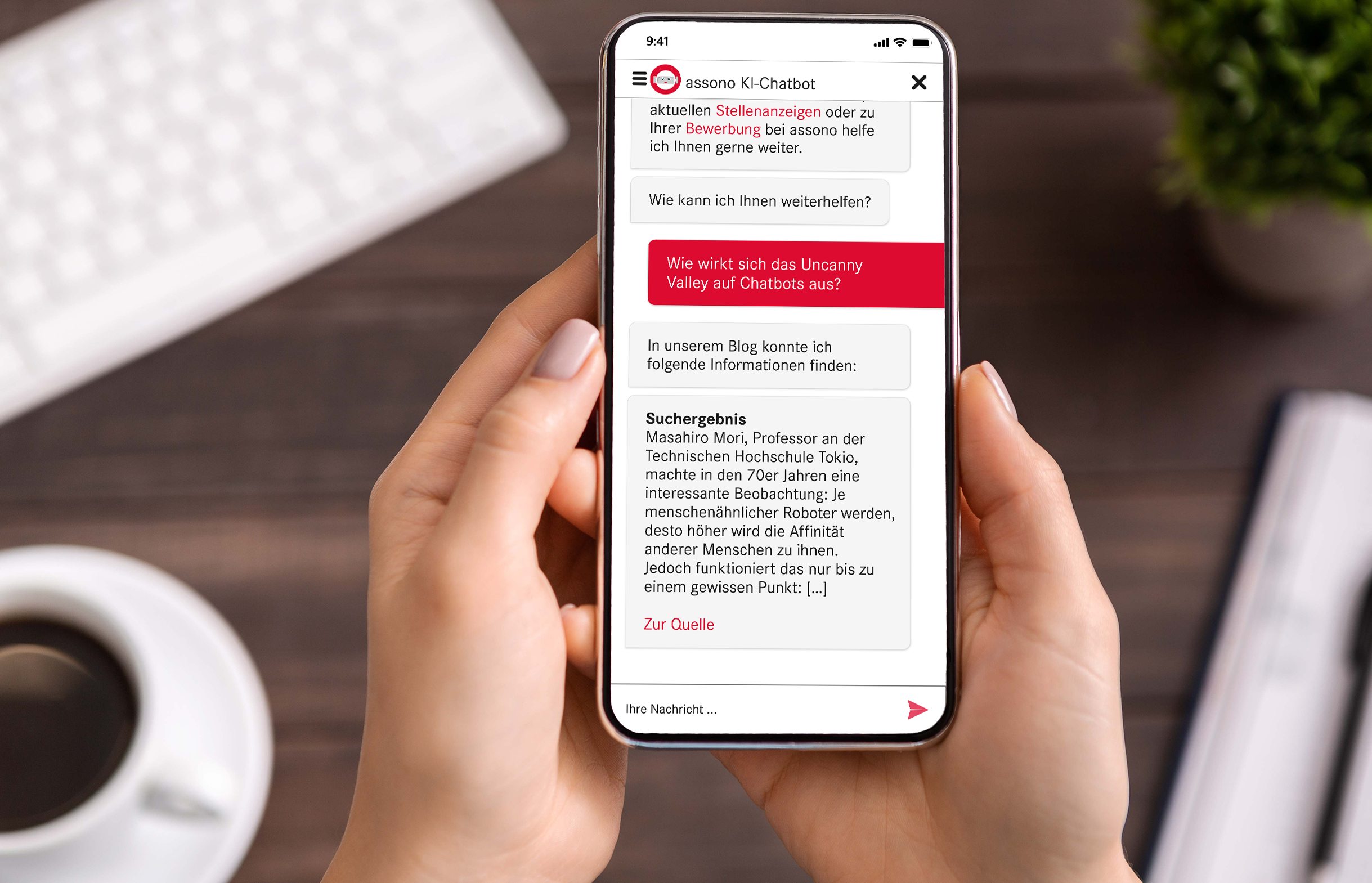
Eine Chatbot-Eingabe wird standardmäßig weitergeleitet, im Gegensatz zur Variante ohne Watson Discovery entscheidet sich jetzt aber meist nach der Konfidenz (der Wahrscheinlichkeit der optimalen Passung der Antwort als Gradmesser) der möglichen Antworten durch den Chatbot, ob diese Eingabe regulär im Dialogsystem verarbeitet oder an Discovery weitergeleitet wird.
Wie auch ein Chatbot beherrscht Discovery die KI-gestützte Möglichkeit, Fragen in natürlicher Sprache zu beantworten. Die Eingaben werden 1-zu-1 als Abfrage an den Dienst gestellt, dieser sucht aus seinen Datenquellen die bestmögliche Antwort in Form einer Passage und eines Quellenlinks heraus. Als Chatbot-Antwort wird diese dann angezeigt und kann direkt im Chat als passend oder nicht passend bewertet werden.
Über das Sammeln und Beobachten der Anfragen ergibt sich die Möglichkeit der Weiterleitung als weiteres Trainingsmaterial nach einer kurzen Prüfung im Dashboard. Hierbei wird zusätzlich eine Rückmeldung zur Discovery-Antwort abgefragt – es besteht also die Möglichkeit eines weiteren Trainings über Rückmeldung von außen, mit einem Sicherheitsmechanismus der Manipulationen verhindert.
Nützliche Tipps
Ein weiterer Punkt der Aufmerksamkeit gilt der bestmöglichen Varianz der Daten: es sollten viele verschiedene vorkommende Typen eines gleichen Inhaltsbereiches trainiert werden, um die bestehenden Unterschiede optimal abzudecken. Werden die Unterschiede allerdings so groß, lohnt es sich u.U., verschiedene Datenkollektionen für unterschiedliche Geschäftsbereiche anzulegen. Ein Unternehmen kann einen globalen Chatbot haben, der aber in unterschiedlichen Datensammlungen auf die respektiven Daten der Geschäftsbereiche Technischer Support, Human Ressources oder Vertrieb spezialisiert ist. Sobald im Kontext des Gespräches ein Inhaltsbereich ausgewählt wurde, können diesem entsprechend auch die unterschiedlichen Datenkollektionen für die Suche bemüht werden. Auch hier gilt: eine hinreichende Untersuchung der notwendigen und vorhandenen Datenbestände ist unabdingbar, um im Chatbot einen optimalen Mehrwert zu bieten, hierbei unterstützen wir Sie sehr gern mit unserer Expertise.
Eine gute Vorauswahl der Datensätze sorgt ganz allgemein für weniger Arbeit beim Training, dies kann z.B. durch die Eingrenzung einer Website-Suche auf FAQs und damit einer Präzisierung erreicht werden. Ebenso können die Auslöser für Discovery-Anfragen über die Konfidenzschwelle der Chatbot-Antwort hinaus individueller eingestellt werden, so kann der Kontext des Gespräches helfen, Schlüsselwörter für die Suche bereitzustellen, um diese zu präzisieren.
Fazit und Anwendungsbeispiele
Chatbots werden durch die Anbindung einer Suchfähigkeit vielseitiger einsetzbar und mit wenig Aufwand bessere Helfer im Alltag. Insbesondere, wenn dies ohne erweiterte technische Kenntnisse umsetzbar ist, fällt bei einer passenden Datengrundlage die Entscheidung für einen mit Discovery erweiterten Chatbot leicht. Die Zeitersparnis wird insbesondere bei größeren Datenmengen sehr deutlich. Einige Beispiele für konkrete Anwendungsfälle könnten die folgenden sein:
Städtewebsites abbilden - Naturgemäß enthalten die Webseiten von Städten und Kreisen eine riesige Menge aktueller Informationen zu allen möglichen Themen rund um das tägliche Leben und die Verwaltung. Bei einer so hohen verfügbaren Datenmenge ist es optimal, einige Unterseiten mit spezifischen Informationen z.B. zu Anlaufstellen und Abläufen bereitzustellen. Es können bspw. sowohl Informations-PDFs zum korrekten Ausfüllen von Anträgen durchsucht werden, als auch die Web-FAQ zur Anmeldung einer Sperrmüllsammlung – da sind den Anwendungsmöglichkeiten kaum Grenzen gesetzt, um der Stadtbevölkerung eine direkte Hilfe an die Hand zu geben.
Montagehilfe - Als Unternehmen, das Maschinen herstellt müssen diejenigen, welche diese aufbauen und konfigurieren, Zugriff auf umfangreiche Handbücher haben. Diese Handbücher können zentral eingelesen und lokal über ein Smartphone durchsucht werden, ohne dass bei konkreten Fragen ellenlange PDFs gesichtet werden müssen – Zeitersparnis durch schnellere Antworten auf konkrete Fragen, auch mit der Option auf eine Anzeige von Grafiken.
Handlungsempfehlungen im medizinischen Bereich - Tipps für Erkrankte und Angehörige bestimmter Krankheiten können bereits auf Webseiten hinterlegt sein, ähnlich FAQs, sind jedoch zu umfangreich, um sie komplett zu durchsuchen. Ein Chatbot mit Discovery bietet eine erste Anlaufstelle, grenzt im Gesprächskontext Thema oder Erkrankung ein und beantwortet konkrete Fragen. Von „Welche Ernährung ist zu empfehlen?“ über die Nennung von Anlaufadressen zur Beratung und Behandlung bis zur Ausgabe von Symptomlisten ist vieles an Information, was echten Mehrwert bringt, schneller verfügbar.
Wir von assono entwickeln KI-Chatbots für jeden Anwendungsfall
Die perfekte Passung eines Chatbots für Ihre Anforderungen und Datenlage zu finden, ist eine Aufgabe, derer wir uns bei assono gern annehmen. Lassen Sie sich in einem kostenlosen Erstgespräch zu Ihrem Anwendungsfall beraten. Vereinbaren Sie dazu gerne einen Termin oder rufen Sie uns an unter +49 4307 900 408. Alternativ können Sie auch einen Termin über unseren KI-Chatbot "asski" vereinbaren. Wir freuen uns auf Sie!





